Understanding machine translation Quality: BLEU scores

What it is
The BLEU score is a string-matching algorithm that provides basic quality metrics for MT researchers and developers. It is likely the most widely used MT quality assessment metric over the last 15 years. While it is largely understood that the BLEU metric has many flaws, it continues to be a primary metric to measure MT system output even today, in the heyday of Neural MT.
BLEU gained popularity because it was one of the first MT quality metrics to report a high correlation with human judgments of quality. Studies have shown that indeed there is a reasonably high correlation, but only when BLEU is properly used. This notion has been challenged often, but the derivative scoring methods that have emerged have yet to unseat its dominance.
Very simply stated, BLEU is a quality metric score for MT systems that attempts to measure the correspondence between a machine translation output and a human translation. The central idea behind BLEU is that the closer a machine translation is to a professional human translation, the better it is.
BLEU scores only reflect how a system performs on the specific set of source sentences and the translations selected for the test. As the selected translation for each segment may not be the only correct one, it is often possible to score good translations poorly. As a result, the scores don’t always reflect the actual potential performance of a system, especially on content that differs from the specific test material.
BLEU does not aim to measure overall translation quality, but rather, focuses on strings. Over the years, people have come to interpret this as a safe measure of quality, but most experts would consider BLEU scores more accurate if comparisons were made at a corpus level rather than a sentence level.
How it works
To conduct a BLEU measurement the following is necessary:
- One or more human reference translations. This should be data that has not been used in building the system (training data) and ideally should be unknown to the MT system developer.
- It is generally recommended that 1,000 or more sentences be used to get a meaningful measurement. Too small a sample set can sway the score significantly with just a few sentences that match or do not match well.
- Automated translation output of the exact same source data set.
- A measurement utility that performs the comparison and score calculation.
Scores are given to individual MT-translated segments – usually sentences – by comparing them with one or a set of good quality human reference translations. When a sentence is translated by two different MT systems, one might produce a translation that matches 75% of the words of the reference correct translation, while the translation of the second MT system might match 55% of the words. Both MT translations might be 100% correct, but the one with the 75% match will be assessed as having provided higher quality, which might seem somewhat arbitrary.
This potential problem is illustrated in the following example. Once we select one of these translations as the only reference, all the other correct translations will score lower.

The BLEU metric scores a translation on a scale of 0 to 1, in an attempt to measure the adequacy and fluency of the MT output. The closer to 1 the test sentences score, the more overlap there is with their human reference translations and thus, the better the system is deemed to be. BLEU scores are often stated on a scale of 1 to 100 to simplify communication, but this should not be confused with the percentage of accuracy.
The MT output would score 1 only if it is identical to the reference human translation. But even two competent human translations of the exact same material may only score in the 0.6 or 0.7 range as they are likely to use different vocabulary and phrasing. We should be wary of very high BLEU scores (in excess of 0.7) as it is probably measuring improperly or overfitting.
The BLEU metric also gives higher scores to sequential matching words. That is, if a string of four words in the MT translation match the human reference translation in the same exact order, it will have more of a positive impact on the BLEU score than a string of two matching words will. This means that an accurate translation will receive a lower score if it uses different, but correct words or matching words in a different word order.
What it’s used for?
Automated quality measurement metrics are important to developers and researchers of data-driven MT technology because of the iterative nature of the MT system development, which requires frequent assessments to provide rapid feedback on the effectiveness of continuously evolving research and development strategies.
Currently we see that BLEU and some of its close derivatives (METEOR, NIST, LEPOR and F-Measure) are also often used to compare the quality of different MT systems in enterprise use settings. This can be problematic since a single point quality score is often not representative of the potential of an evolving customized enterprise MT system. Also, such a score does not consider overall business requirements in an enterprise use scenario, where many other factors, such as workflow, integration and processes, are important. What is considered useful MT quality in the enterprise context varies greatly depending on the needs of the specific use case.
Most of us would agree that competent human evaluation is the best way to understand the output quality implications of different MT systems. However, human evaluation is generally slower, less objective and more expensive, and thus may not be viable in many production use scenarios, where multiple comparisons need to be made on a constant and ongoing basis.
Automated metrics like BLEU provide a quick, though often dirty, quality assessment that can be useful to those who understand its basic mechanics. However, its basic flaws and limitations must be understood to avoid over-reaching or erroneous quality assessment conclusions.
Quality scores can be used in two very different contexts:
- R&D: Comparing different versions of an evolving MT system during the development of the production system
- Buyer: Comparing different MT systems and deciding which one is best
Data-driven MT systems cannot be built without automated metrics to measure ongoing progress. MT system builders are constantly trying new data management techniques, algorithms and data combinations to improve systems as they need quick and frequent feedback on whether or not a particular strategy is working. Standardized, objective and relatively rapid means of assessing quality are necessary for the system development process in this technology. If the evaluation is done properly, tests can also be useful to understand how a system evolves over time.
2.MT buyer needs
As there are many MT technology options available today, BLEU and its derivatives are sometimes used to compare and select MT vendors and systems. The use of BLEU in this context is much more problematic and prone to erroneous conclusions since comparisons are often made between apples and oranges. The most common issue in interpreting BLEU is the lack of awareness and understanding that there will be a positive bias towards one MT system if the system has been trained on the test data or has been used to develop the test data set itself.
What it means
All inferences on what the BLEU score means should take into consideration the existing set of test sentences. It is very easy to see how BLEU can be used incorrectly, and the localization industry abounds with examples of incorrect, erroneous and even deceptive use.
Measuring translation quality is a difficult task because there is no absolute way to measure how much more correct one translation choice is than another. MT is a particularly difficult AI challenge because computers prefer binary outcomes, and translation rarely, if ever, has only one single correct outcome. There can be as many correct translations as there are translators and, therefore, using one human reference to measure the quality of an automated translation solution presents issues.
BLEU is actually not much more than a method to measure the similarity between two text strings. To infer that this metric, which applies no linguistic consideration or intelligence, can predict past or future translation quality performance is a stretch.
How it’s criticized
While BLEU is very useful to those who build and refine MT systems, its value as a tool to compare different MT systems is much more limited since it can be manipulated and create a bias.
CSA Research and leading MT experts have pointed out for over a decade that [BLEU] metrics are artificial and irrelevant for production environments. One of the biggest reasons is that the scores are relative to particular references. Changes that improve performance against one human translation might degrade it with respect to another.” (CSA Blog on BLEU Misuse, April, 2017)
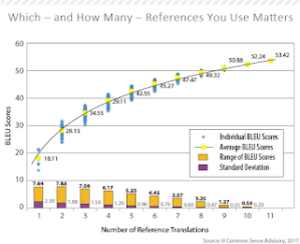
Criticisms of BLEU that should be understood before the metric can be used effectively include:
- As mentioned above, BLEU only measures direct word-to-word similarity and the extent to which word clusters in two sentences are identical. Accurate translations that use different words may score poorly simply because they don’t match the selected human reference.
- There is no consideration of paraphrases or synonyms, so scores can be misleading in terms of overall accuracy. For example, "wander" doesn't get partial credit for "stroll," nor does "sofa" for "couch."
- Nonsensical language that contains the right phrases in the wrong order can score high. For example, depending on the reference translation, "Appeared calm when he was taken to the American plane, which will to Miami, Florida" might get the very same score as "Was being led to the calm as he was would take carry him seemed quite when taken."
- According to this white paper, more reference translations do not necessarily help.
You can read more about these and other problems in this article and this critical academic review.
The problems are further exacerbated with the Neural MT (NMT) technology, which can often generate excellent translations that are quite different from the reference and thus score poorly. When human evaluations are done, it has been found that lower BLEU scoring NMT systems are actually preferred over higher BLEU scoring Statistical MT systems.
Some new metrics (ChrF, SacreBLEU, Rouge) are attempting to replace BLEU, but none have gathered any significant momentum, and the best way to evaluate NMT system output today is still well structured human assessments.
For post-editing work assessments there is a growing preference for Edit Distance scores to more accurately reflect the effort involved, even though it too is far from perfect.
How it should be used
As would be expected, using multiple human reference translations will result in higher scores as the MT output has more variations to match against. In its annual MT competition, the NIST (National Institute of Standards & Technology) used BLEU as an approximate indicator of quality with four human reference sets to ensure that some variance in human translation was captured and allowed for more accurate assessments of the MT solutions being evaluated. They also defined the test and evaluation process carefully, and as a result, comparing MT systems under such rigor and purview was meaningful. This has not been true for many of the published comparisons done since.
It is important to carry out comparison tests in an unbiased, scientific manner to get a true view of where a system stands against competitive alternatives. The test set should be unknown to all the systems that are involved in the measurement. If a system is trained with the sentences in the test set, it will do well on the test, but probably not as well on data that it has not seen before. Many recent comparisons score MT systems on news-related test sets that may also have been used in training by MT developers. But a good score on the news domain may not be especially useful for an enterprise use case that is heavily focused on IT, pharma, travel or any other domain.
As stated before, modern MT systems are built by training a computer with examples of human translations. As more human translation data is added, systems should generally get better in quality. However, new data can also have a negative effect, especially if it is “noisy” or “dirty.”
System developers need to measure the quality impact rapidly and frequently to make sure they are in fact improving the system and making progress. When used to evaluate the relative merit of different system building strategies, BLEU can be quite effective as it provides very quick feedback that enables MT developers to refine and improve translation systems quality on a continuous and long term basis.
The Future of Quality Metrics
The MT community has found that supposedly improved metrics like METEOR, LEPOR, and others have not really gained any momentum. In addition, BLEU and its issues are now more clearly understood, and thus it is more reliable, especially if used in combination with supporting human assessments. Also, many buyers today realize that MT system performance on their specific subject domains and content for different use cases matters much more than how generic systems might perform on news stories.
In spite of all the limitations identified above, BLEU continues to be a basic metric used by most, if not all MT developers today. However, most expert developers now regularly use human evaluation on smaller sets of data to ensure that they indeed have true and meaningful BLEU scores. In addition, to truly assess the quality of an MT system, no single measure should be trusted. As a best practice, any evaluation should be related to the specific use case.
Stay tuned
In upcoming posts in this series, we will continue to explore the issue of MT quality assessment from a broad enterprise needs perspective. More informed practices will result in better outcomes and significantly improved MT deployments that leverage the core business mission to solve high-volume multilingual challenges more effectively.
Kirti Vashee
All from Kirti VasheeRelated Articles
