Understanding BERT
26 Jun 2020
3 min read

As momentum continues to grow in the field of machine learning, we're being treated to more and more innovations and breakthroughs. Perhaps the most significant natural language processing advance in the past 12 months is something called BERT. But what is BERT, and what impact will it have on the industry? I recently sat down with RWS's machine learning (ML) and natural language processing (NLP) expert, Dragos Munteanu, and asked him a few questions to help us all better understand BERT and its far-reaching impact on language and translation.
Firstly, what is BERT?
Last year, Google released a neural network-based technique for NLP pre-training called Bidirectional Encoder Representations from Transformers (BERT). While that sounds like quite a mouthful, BERT is a significant, and possibly even revolutionary step forward for NLP in general. There has been much excitement in the NLP research community about BERT because it enables substantial improvements in a broad range of different NLP tasks. Simply put, BERT brings considerable advances to many tasks related to natural language understanding (NLU).
The following points help us to understand the salient characteristics of the innovation, driven by BERT:
- BERT is pre-trained on a large corpus of annotated data that enhances and improves subsequent NLP tasks. This pre-training step is half the magic behind BERT's success. As we train a model on a large text corpus, the model starts to pick up the more in-depth and intimate understandings of how the language works. This knowledge is the swiss army knife that is useful for almost any NLP task. For example, a BERT model can be fine-tuned toward a small data NLP task like question answering and sentiment analysis, resulting in substantial accuracy improvements compared to training on smaller datasets from scratch. BERT allows researchers to get state-of-the-art results even when very little training data is available.
- Words are problematic because plenty of them are ambiguous, polysemous, and synonymous. BERT is designed to help solve ambiguous sentences and phrases that are made up of lots and lots of words with multiple meanings.
- BERT will help with things like:
- Named entity determination
- Coreference resolution
- Question answering
- Word sense disambiguation
- Automatic summarization
- Polysemy resolution
- BERT is a single model and architecture that brings improvements in many different tasks that previously would have required the use of multiple different models and architectures.
- BERT also provides a much better contextual sense, and thus increases the probability of understanding the intent in search. Google called this update "the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search."
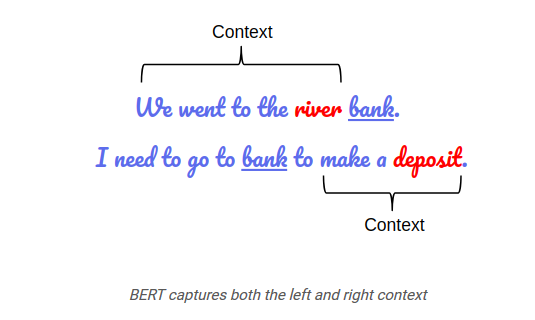
While BERT is a significant improvement in how computers 'understand' human language, it is still far away from understanding language and context in the same way that humans do. We should, however, expect that BERT will have a significant impact on many understanding focused NLP initiatives. The General Language Understanding Evaluation benchmark (GLUE) is a collection of datasets used for training, evaluating, and analyzing NLP models relative to one another. The datasets are designed to test a model's language understanding and are useful for evaluating models like BERT. As the GLUE results show, BERT makes it possible to outperform humans even in comprehension tasks previously thought to be impossible for computers to outperform humans.
Can you describe in layman's terms what BERT is and why there is so much excitement about it?
BERT combines three factors in a powerful way. First, it is a very large, attention-based neural network architecture known as "Transformer Encoder" (Transformer networks are the basis of our NMT 2.0 language pairs). Second, one uses a "fill in the blank" method to train the network, where you remove words randomly from a paragraph then the system tries to predict them. Third, it is trained on massive amounts of monolingual text, usually English. There are also variants trained with French, German, Chinese, and even one trained with 104 different languages (but not with parallel data).
The result is a powerful representation of language in context, which can be "fine-tuned" (quickly adapted) to perform many challenging tasks previously considered hard for computers, i.e., requiring world knowledge or common sense.
Some feel that BERT is good for anything related to NLP, but what are the specific NLP problems that BERT has best solved?
BERT and other similar models (RoBERTa, OpenAI GPT, XL-Net) are state of the art on many NLP tasks that require classification, sequence labeling, or similar digesting of text, e.g., named entity recognition, question answering, sentiment analysis. BERT is an encoder, so it digests data, but by itself, it does not produce data. Many NLP tasks also include a data creation task (e.g., abstractive summarization, translation), and these require an additional network and more training.
I am aware that several BERT inspired initiatives are beating human baselines on the GLUE (General Language Understanding Evaluation) leaderboard. Does this mean that computers understand our language?
Neural networks learn a mapping from inputs to outputs by finding patterns in their training data. Deep networks have millions of parameters and thus can learn (or "fit") quite intricate patterns. This is really what enables BERT to perform so well on these tasks. In my opinion, this is not equivalent to an understanding of the language. There are several papers and opinion pieces that analyze these models' behavior on a deeper level, specifically trying to gauge how they handle more complex linguistic situations, and they also conclude that we are still far from real understanding. Speaking from the RWS experience training and evaluating BERT based models for tasks such as sentiment analysis or question answering, we recognize these models perform impressively. However, they still make many mistakes that most people would never make.
If summarization is a key strength of BERT – do you see it making its way into the Content Assistant capabilities that RWS has as the CA scales up to solve larger enterprise problems related to language understanding?
Summarization is one of the critical capabilities in CA, and one of the most helpful in enabling content understanding, which is our overarching goal. We currently do extractive summarization, where we select the most relevant segments from the document. In recognition of the fact that different people care about various aspects of the content, we implemented an adaptive extractive summarization capability. Our users can select critical phrases of particular interest to them, and the summary will change to choose segments that are more related to those phrases.
Another approach is abstractive summarization, where the algorithm generates new language that did not exist in the document being summarized. Given its powerful representation, transformer networks like BERT are in a good position to generate text that is both fluent and relevant for the document's meaning. In our experiments so far, however, we have not seen compelling evidence that abstractive summaries facilitate better content understanding.
I have read that while there are some benefits to trying to combine BERT-based language models into NMT systems; however, the process to do this seemed rather complicated and expensive in resource terms. Do you see BERT influenced capabilities coming to NMT in the near or distant future?
Pretrained BERT models can be used in several different ways to improve the performance of NMT systems, although there are various technical difficulties. BERT models are built on the same transformer architecture used in the current state-of-the-art NMT systems. Thus, in principle, a BERT model can be used either to replace the encoder part of the NMT system or to help initialize the NMT model's parameters. One of the problems is that, as you mention, using a BERT model increases the computational complexity. And the gains for MT are, so far, not that impressive; nowhere near the kind of benefits that BERT brings on the GLUE-style tasks. However, we continue to look into various ways of exploiting the linguistic knowledge encoded in BERT models to make our MT systems better and more robust.
Others say that BERT could help in developing NMT systems for low-resource languages. Are the capabilities to transfer the learning from monolingual data likely to affect our ability to see more low-resource language combinations shortly?
One of the aspects of BERT that is most relevant here is the idea of training representations that can be quickly fine-tuned for different tasks. If you combine this with the concept of multi-lingual models, you can imagine an architecture/training procedure that learns, and builds models relevant to several languages (maybe from the same family), which then can be fine-tuned for any language in the family with small amounts of parallel data.
What are some of the specific capabilities, resources and competence that RWS has that will enable the company to adopt this kind of breakthrough technology faster?
Our group has expertise in all the areas involved in developing, optimizing, and deploying NLP technologies for commercial use cases. We have world-class researchers who are recognized in their respective fields, and regularly publish papers in peer-reviewed conferences.
We have already built a variety of NLP capabilities using state-of-the-art technology: summarization, named entity recognition, question generation, question answering, sentiment analysis, sentence auto-completion. They are in various stages in the research-to-production spectrum, and we continue to develop new ones.
We also have expertise in the deployment of large and complex deep learning models. Our technology is designed to optimally use either CPUs or GPUs, in either 32-bit or 16-bit mode, and we understand how to make quality-speed trade-offs to fulfill the various use cases of our customers.
Last but not least, we foster close collaboration between research, engineering, and product management. Developing NLP capabilities that bring concrete commercial value is as much an art as it is a science, and success can only be attained through breadth of expertise and deep collaboration.
To learn more about RWS's Machine Translation and what it can do for you, click here. And if you'd like to join the conversations around developments in Machine Translation, sign up to the RWS Community.
About Dragos Munteanu
Dragos Munteanu is currently managing the end-to-end development life cycle of RWS's machine translation products, with a focus on continuous translation quality improvement via innovation in algorithms and advancement in scalability. He has extensive knowledge in statistical machine translation, machine learning and natural language processing. Dragos has over ten years of experience in the translation industry with significant contributions as both scientist and product manager. He has a PhD in computer science from the University of Southern California and an MBA from the University of California Los Angeles.

Kirti Vashee
All from Kirti VasheeRelated Articles
